一、问题现象
hive 执行sql 报不能关闭文件,因为福本数不足
ERROR : FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Unable to close file because the last blockBP-1167696284-10.64.2.34-1562655739823:blk_1690213888_1342501992 does not have enough number of replicas.
INFO : Completed executing command(queryId=hive_20230309060531_6c27a60f-5731-491e-a0be-41be74e8bffd); Time taken: 27.875 seconds
Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Unable to close file because the last blockBP-1167696284-10.64.2.34-1562655739823:blk_1690213888_1342501992 does not have enough number of replicas.
taskId-3380371,error
二、持续时间
每天不定期发生
三、问题原因
从报错的情况看是 hive 执行完的结果在写hdfs文件的时候 由于副本数不够导致 关闭文件失败导致的。
那么这个是由于什么原因导致的呢? DataNode上报块写成功通知延迟的原因可能有:网络瓶颈导致、CPU瓶颈导致。
一般出现上述现象,说明集群负载很大,通过调整参数只是临时规避这个问题,建议还是降低集群负载。例如:避免把所有CPU都分配MR跑任务。
如果我们要想彻底的明白原理,还需要对hdfs写入文件的流程 加以了解
看到hdfs 写文件流程最终要通知NameNode 也写成了,上面报错的主要原因就是通知namenode的过程当中超时了
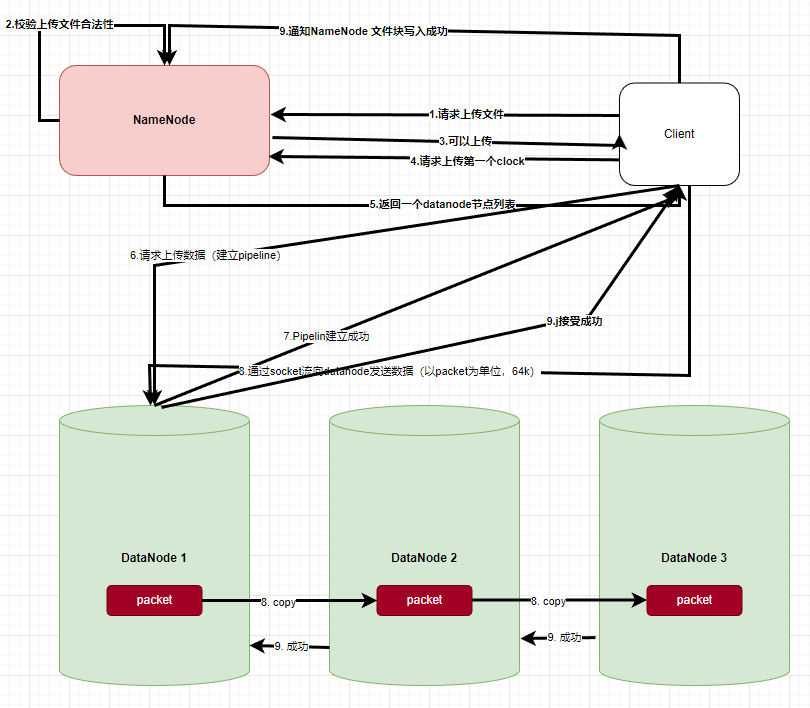
这让我想起来很多 logstash webhdfs 关闭gz 压缩文件失败的原因也有可能是这个导致的
让我们读一下 hdfs 写文件的源码,最后确认文件的流程。
// 全类名 :org.apache.hadoop.hdfs.DFSOutputStream
// hadoop 3.0.0 版本代码
protected void completeFile(ExtendedBlock last) throws IOException {
long localstart = Time.monotonicNow();
// 获取配置
final DfsClientConf conf = dfsClient.getConf();
// int LOCATEFOLLOWINGBLOCK_INITIAL_DELAY_MS_DEFAULT = 400;
// 获取默认间隔 400ms
long sleeptime = conf.getBlockWriteLocateFollowingInitialDelayMs();
boolean fileComplete = false;
// int LOCATEFOLLOWINGBLOCK_RETRIES_DEFAULT = 5;
// 重试次数 默认为5
int retries = conf.getNumBlockWriteLocateFollowingRetry();
while (!fileComplete) {
// 获取关闭文件是否成功 成功的话 下次 循环直接退出
fileComplete =
dfsClient.namenode.complete(src, dfsClient.clientName, last, fileId);
if (!fileComplete) {
// /** Default value for IPC_CLIENT_RPC_TIMEOUT_KEY. */
// public static final int IPC_CLIENT_RPC_TIMEOUT_DEFAULT = 0;
// 获取rpc 超时时间 默认为 0
final int hdfsTimeout = conf.getHdfsTimeout();
// 判断客户端是否运行着 或者 超时时间大于 0
if (!dfsClient.clientRunning
|| (hdfsTimeout > 0
&& localstart + hdfsTimeout < Time.monotonicNow())) {
String msg = "Unable to close file because dfsclient " +
" was unable to contact the HDFS servers. clientRunning " +
dfsClient.clientRunning + " hdfsTimeout " + hdfsTimeout;
DFSClient.LOG.info(msg);
throw new IOException(msg);
}
try {
// 如果重试次数剩余到 0 就抛出异常 结束
if (retries == 0) { // 结束while 循环
throw new IOException("Unable to close file because the last block"
+ last + " does not have enough number of replicas.");
}
retries--;
// 睡上 一段时间
Thread.sleep(sleeptime);
// 并对间隔时间翻倍
sleeptime *= 2;
if (Time.monotonicNow() - localstart > 5000) { // 当大于5秒的时候打印日志
DFSClient.LOG.info("Could not complete " + src + " retrying...");
}
} catch (InterruptedException ie) {
DFSClient.LOG.warn("Caught exception ", ie);
}
}
}
四、解决问题
- 降低Data Node 节点上 NodeManage 节点的 cpu 使用个数
- 修改hdfs参数
-- 默认的参数为5
<property>
<name>dfs.client.block.write.locateFollowingBlock.retries</name>
<value>8</value>
</property>
说明:调大dfs.client.block.write.locateFollowingBlock.retries参数值,在节点繁忙时会延长文件close的等待时间,正常写入不受影响。
- 可以把这个参数在客户机上配置,并不一定非低修改hdfs配置,如在 hive-site或logstash webhdfs 当中配置
<property>
<name>dfs.client.block.write.locateFollowingBlock.retries</name>
<value>8</value>
</property>
五、参考资料
https://help.aliyun.com/document_detail/468629.html
https://support.huaweicloud.com/trouble-mrs/mrs_03_0081.html